Reproducibility and transparency in academia, and implications for statistical agencies
2026-04-02
Follow along

larsvilhuber.github.io/transparency-statistical-agencies/ (HTML zipped, PDF)
AEA Journals

What is a replication package?

AEA policy

Historically
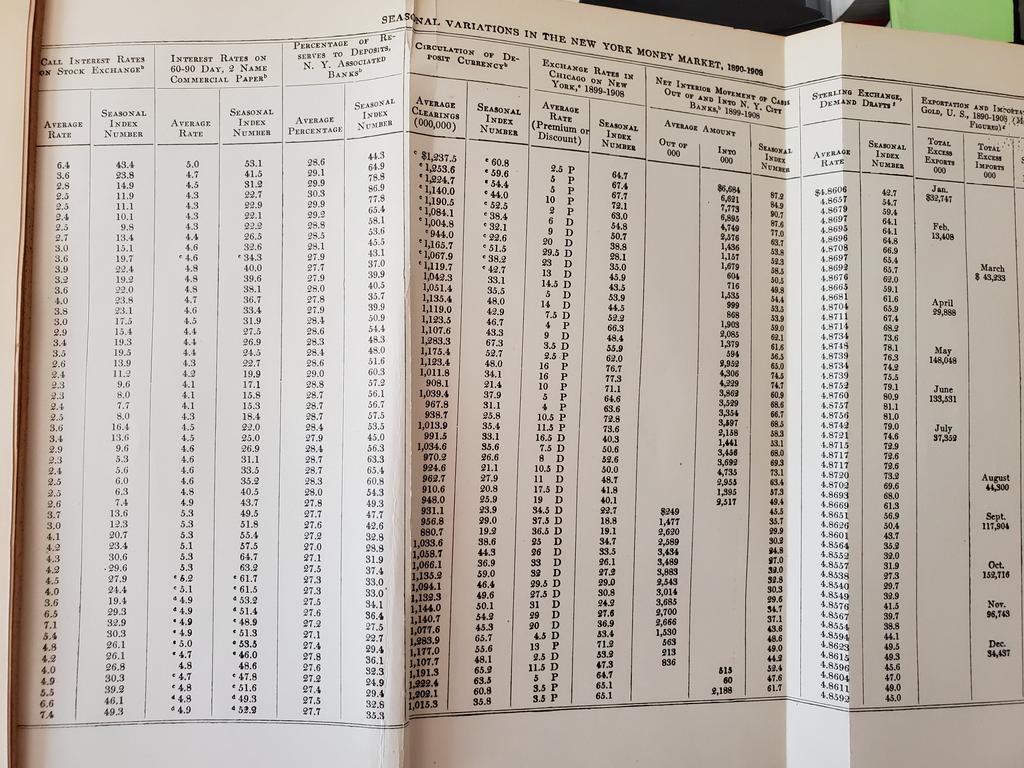
AER 2011 thanks to Stefano Dellavigna
Modern preservation
How often confidential?
AER articles in 2024 (Vilhuber, 2025, Revue Economique)
Who is the target person?

Student replicators
Who is the target person?
Over the past 6 years, over 170 undergraduate students have been involved in verifying these articles.
- Economics, biostatistics, sociology
- Typically recruited in sophomore or junior year, but will consider freshmen through master’s students
Data Editors
- American Economic Association (8)
- Econometric Society (3)
- Canadian Journal of Economics (1)
- Royal Economic Society (2)
- Western Economic Association International (1)
- European Economic Association (1)
- Review of Economic Studies (1)
- Journal of the European Economic Association (1)
- Journal of Political Economy (3)

Common policies
https://social-science-data-editors.github.io/
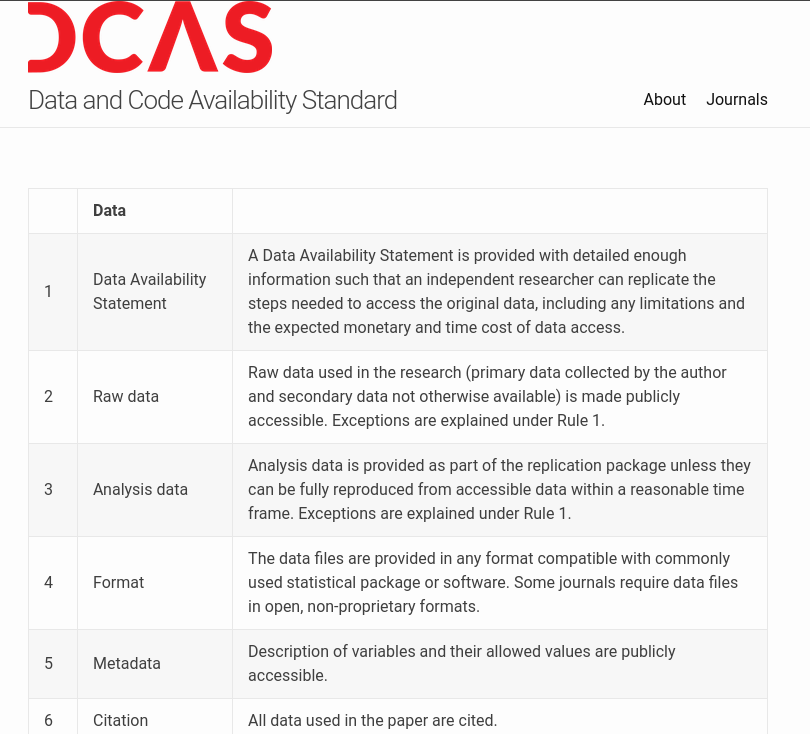

Elsewhere: Political Science
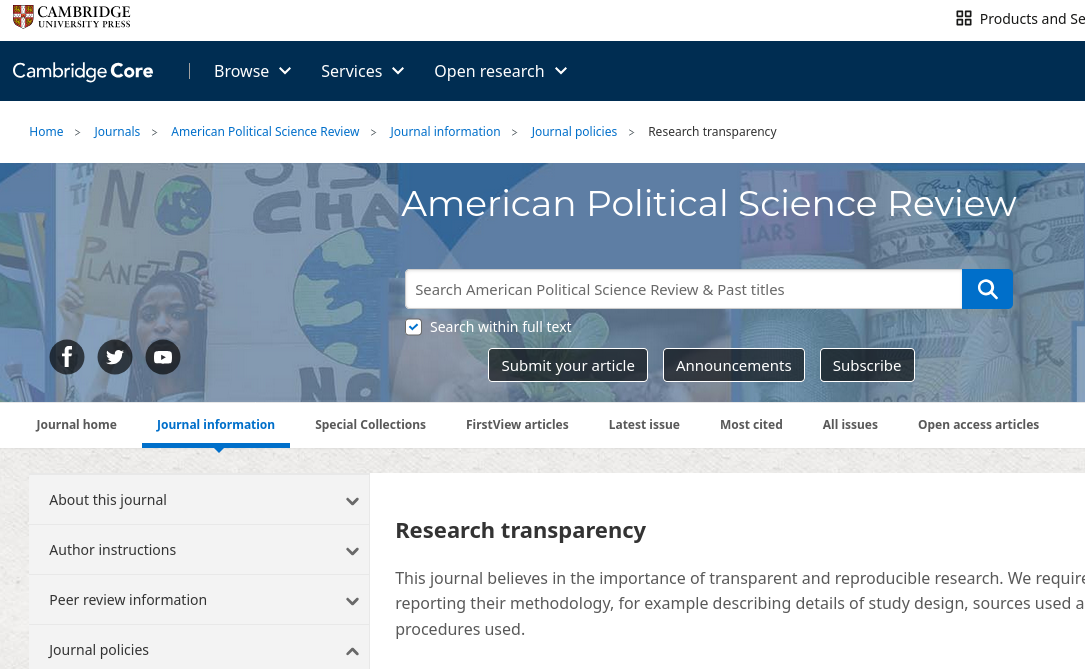

Elsewhere: Sociology

Agency efforts
Agency efforts


Joint Statement
Joint Statement on Commitment to Scientific Integrity and Transparency
- Principle 2: a Federal statistical agency must have credibility with those who use its data and information;
- Principle 3: a Federal statistical agency must have the trust of those whose information it obtains;

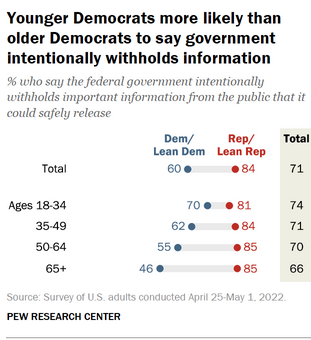
Waning trust
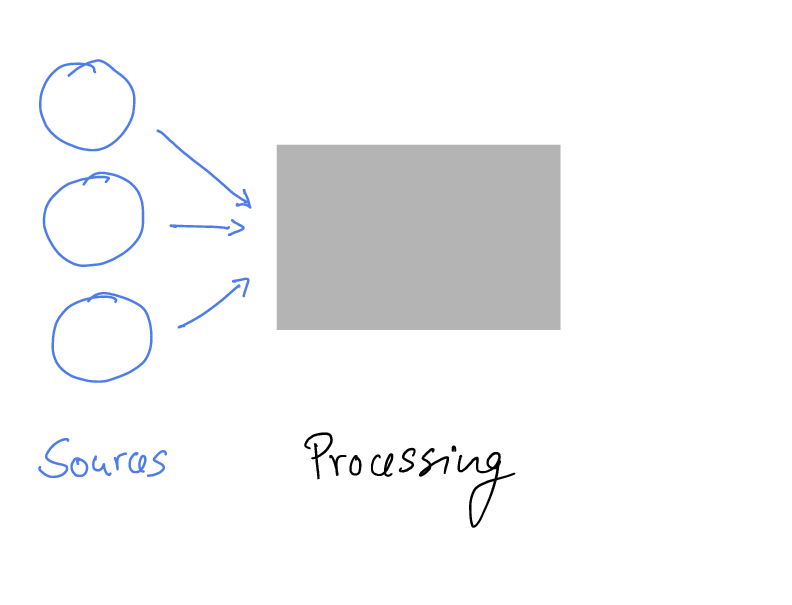
Computational Reproducibility and Official Statistics
Agencies do provide detailed information on sources
- Surveys
- Administrative data

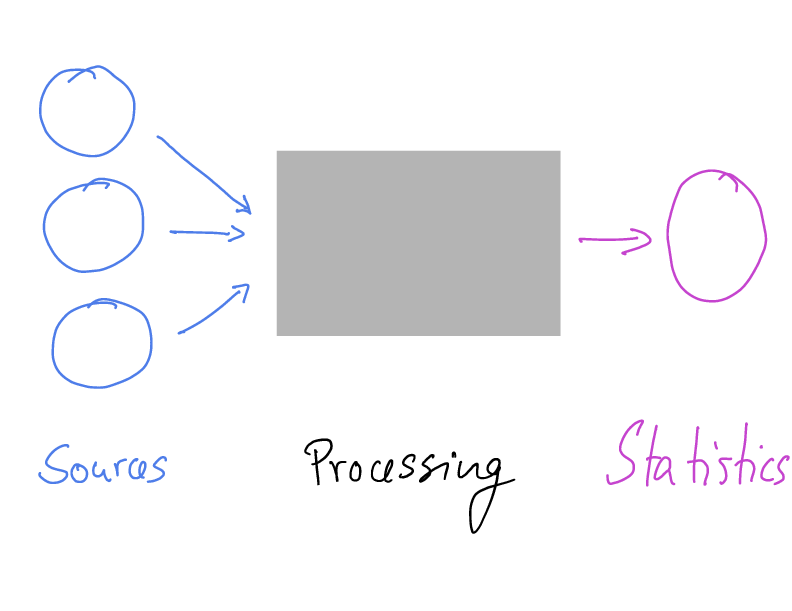
Computational Reproducibility and Official Statistics
But: Availability of “computing instructions”?
- Code for cleaning, aggregation, imputation
- Including for disclosure avoidance
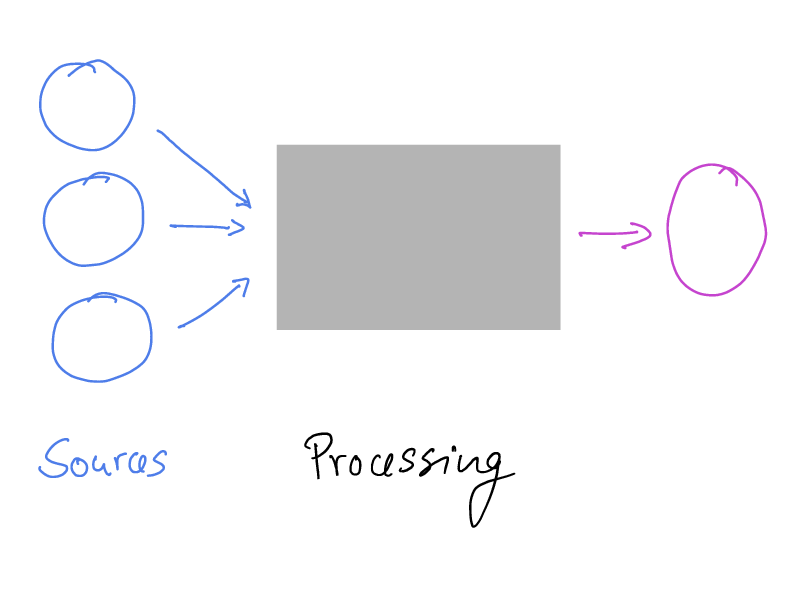
Computational Reproducibility and Official Statistics
But: Availability of reliable, trusted data archives
- Of released data – ability to reproduce downstream uses
- Of source data – ability to reproduce released data
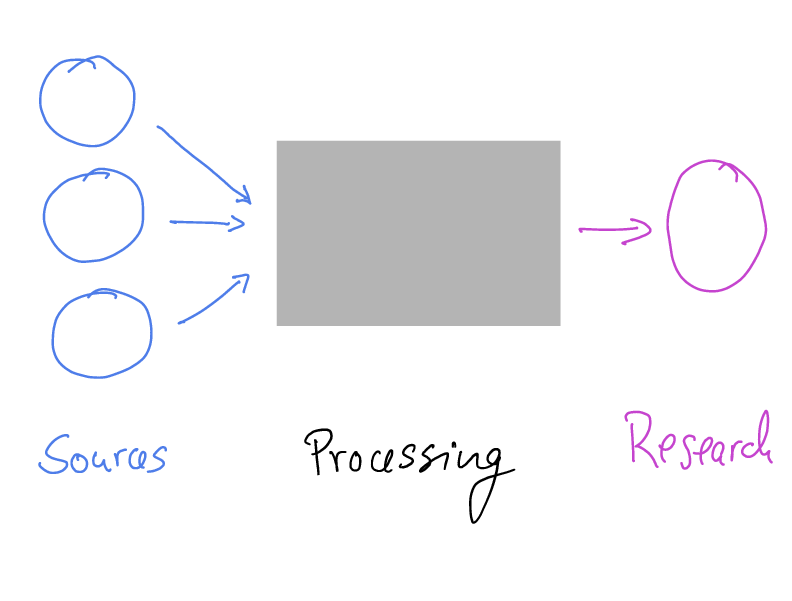
The analogy
The analogy
The analogy
FAIR Principles
FAIR:
- Findable
- Accessible
- Interoperable
- Reusable
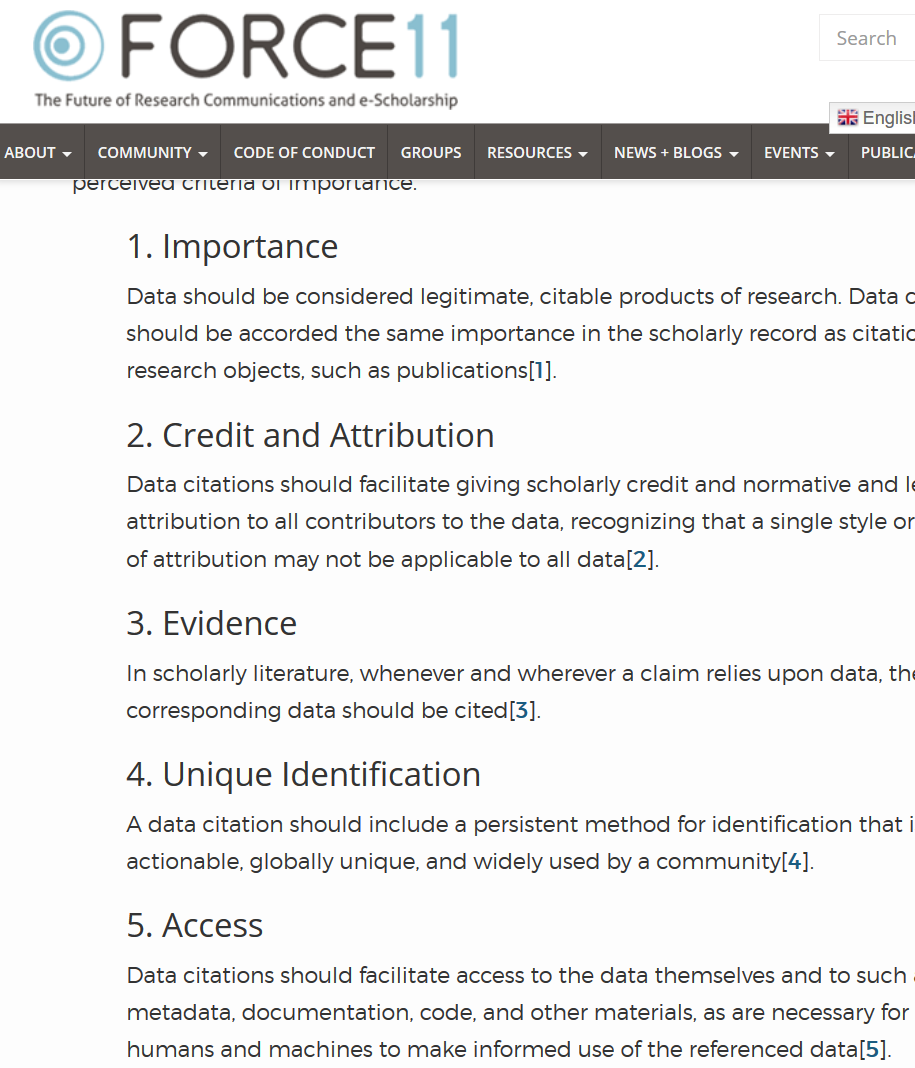
Data Citation Principles
An example from ERS

Website
Website
Sources

High-level description of sources
Sources
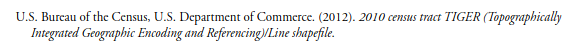
Sources are cited!
Methods

High-level description of methods, but no (obvious) code
Methods

Some methods - R code - is cited
Own citation?

Own citation does not include a URL
Findability?
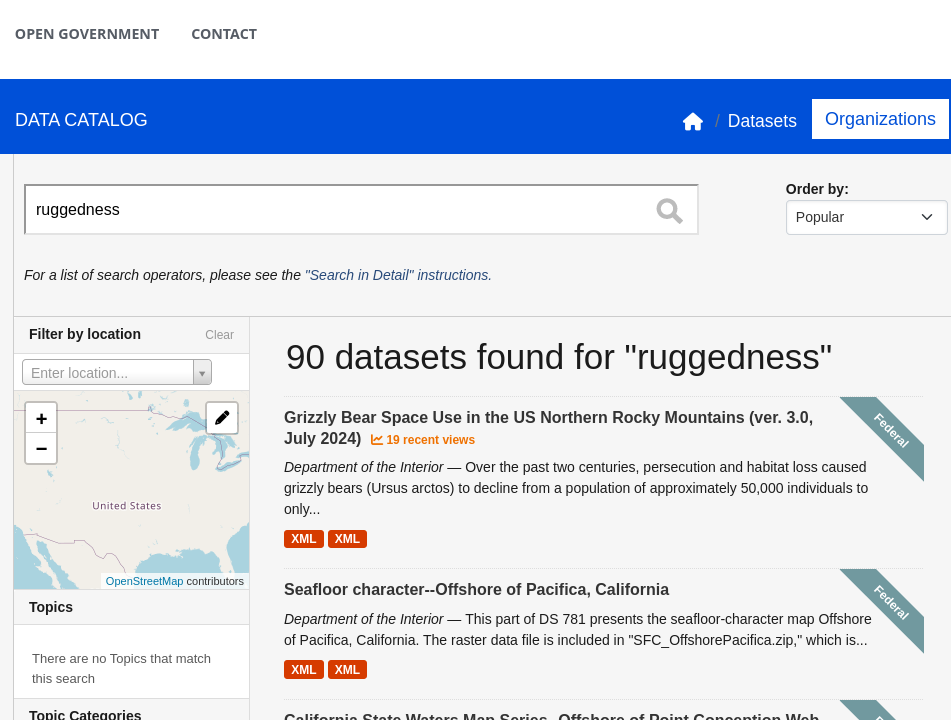
Findability?
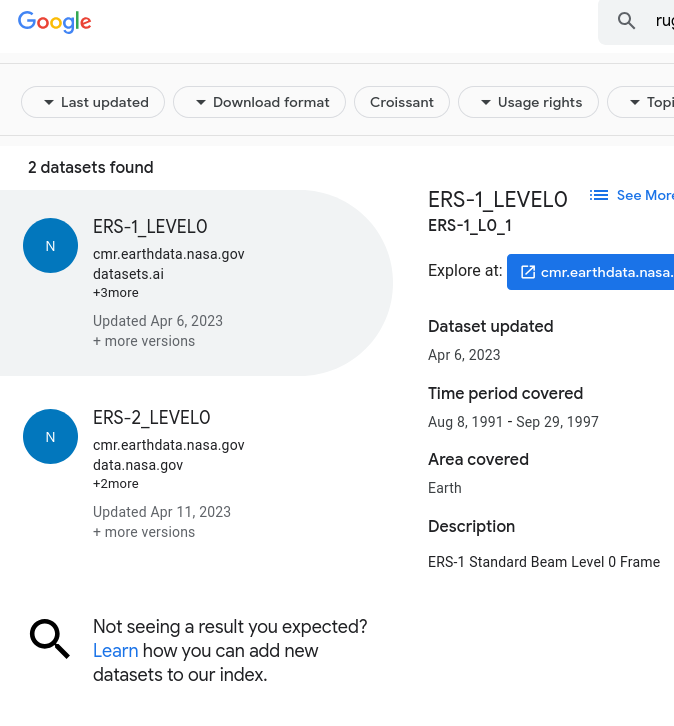
Not even close.
Consider the case of Gino

Francesca Gino
The case of Gino
- Several articles were investigated by third parties (Data Colada, in particular 9), and found to be problematic

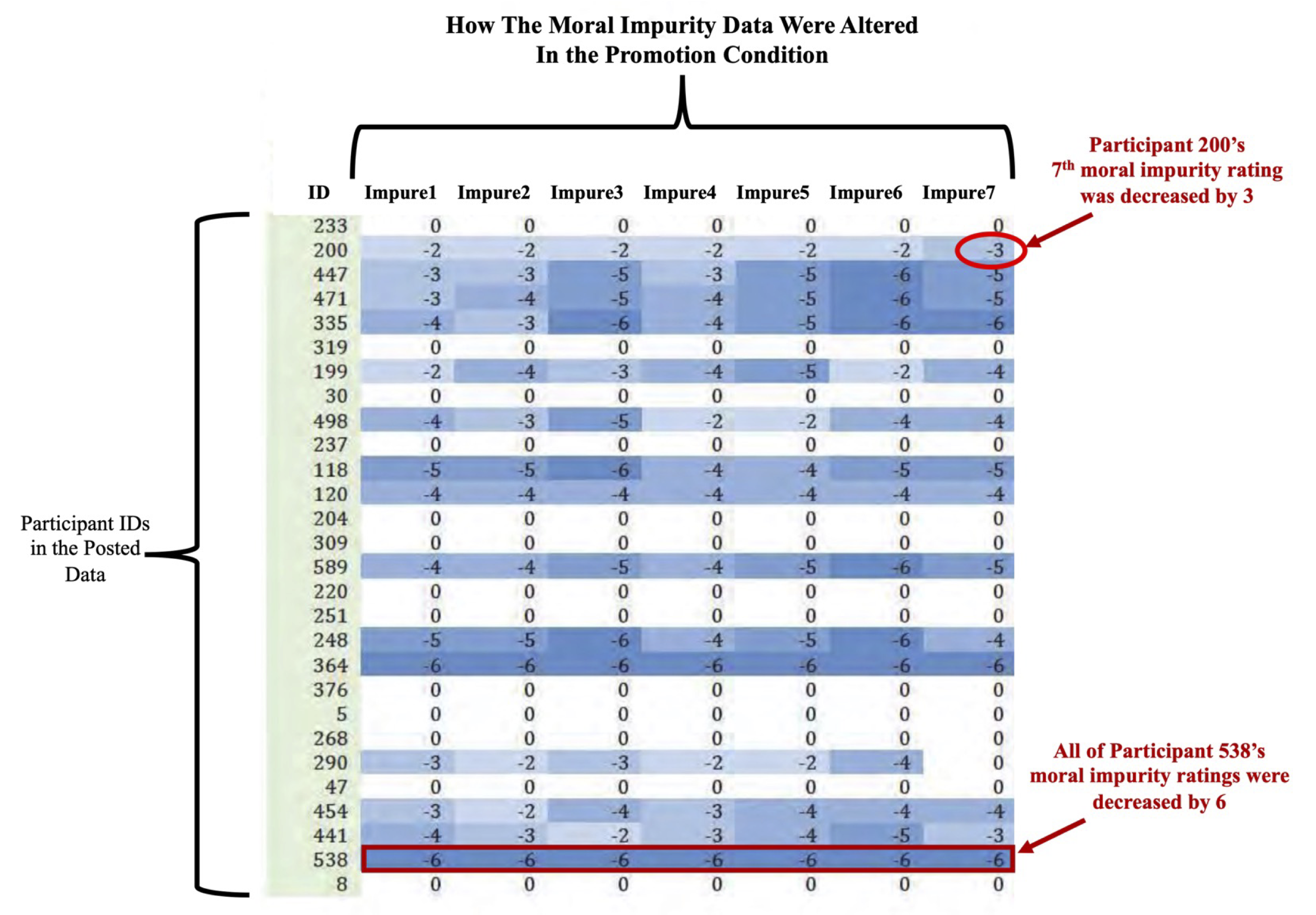
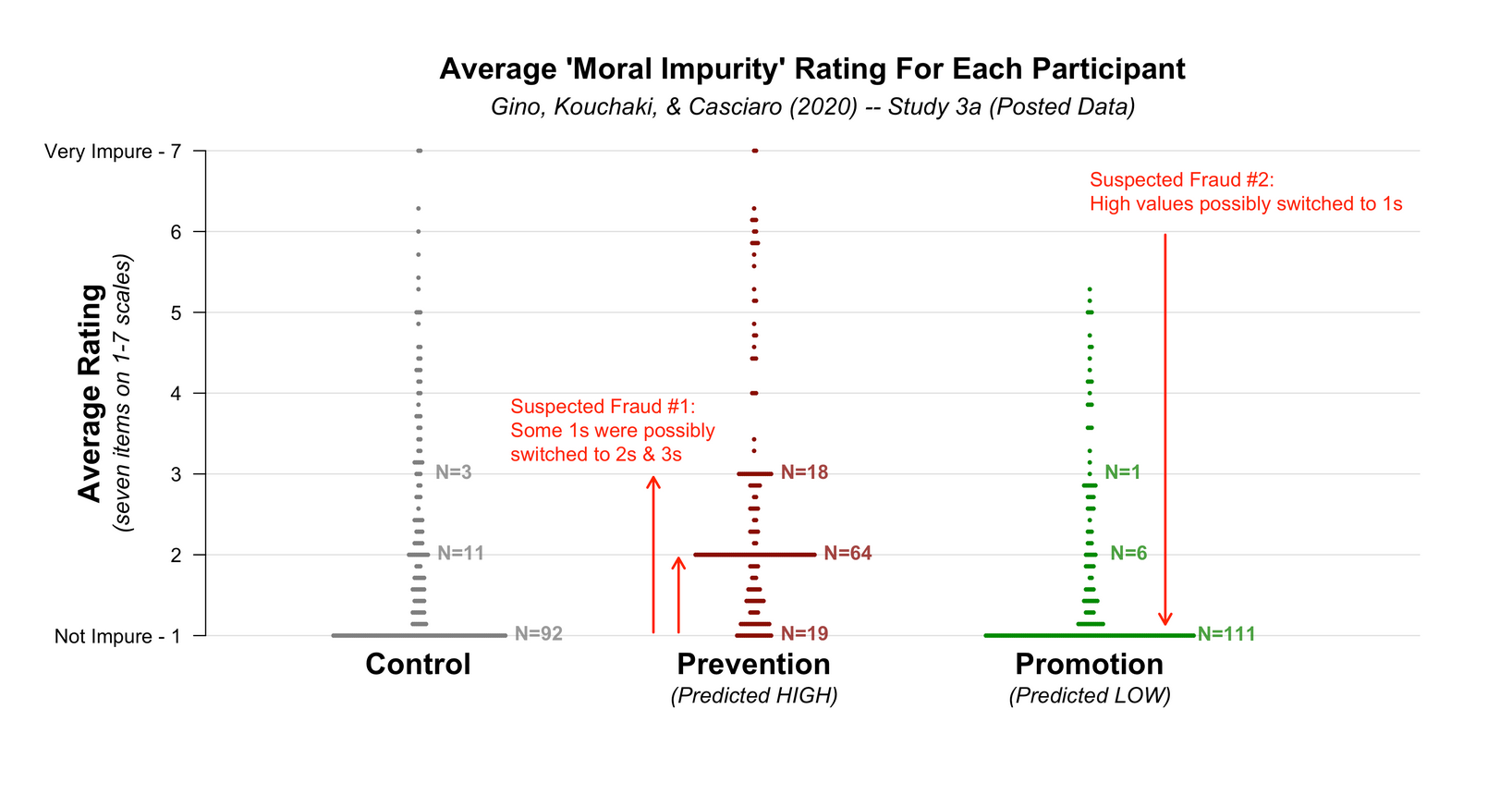
The case of Gino
- At least one of them had manipulated data AFTER it had been collected, BEFORE it had been analyzed.
Generic survey processing
Generic survey processing
Requiring transparency in academia
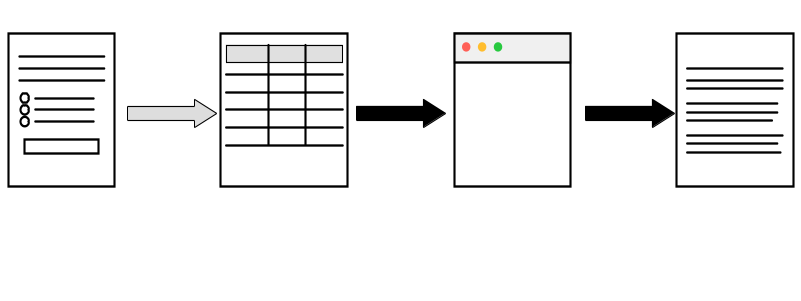
Verifying transparency in academia
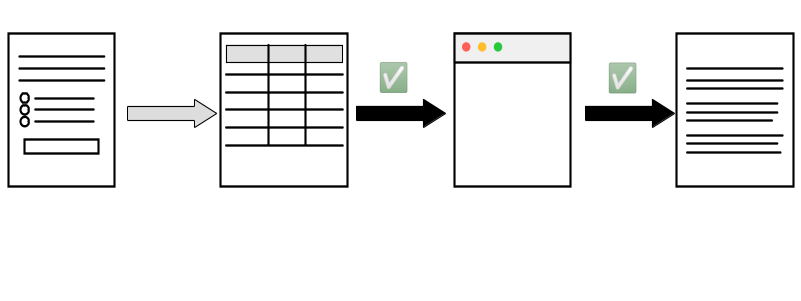
Verification by others
- Pre-publication: cascad
- Post-publication: Data Colada, Institute for Replication
Verification by institutions
Taking it a step further
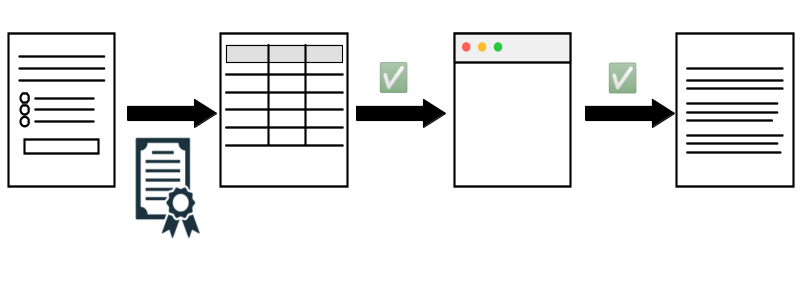
Does not prevent all fraud
Toronto researcher loses Ph.D.

MIT student makes up firm data

Can Assurances be created for Statistical Agencies?
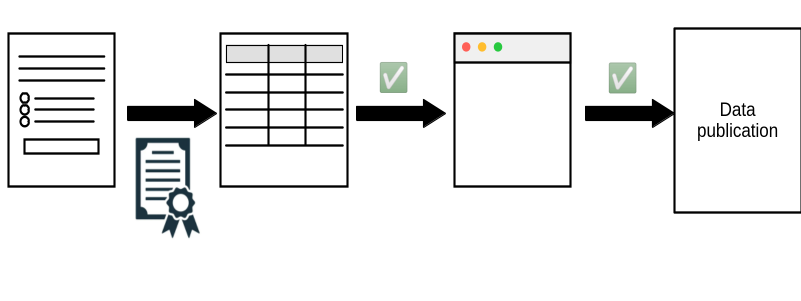
How to document the full process?
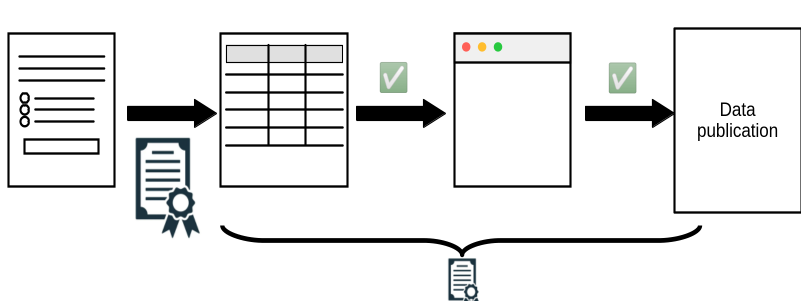
A sketch: Transparency Certified
https://transparency-certified.github.io/
CASD data catalog
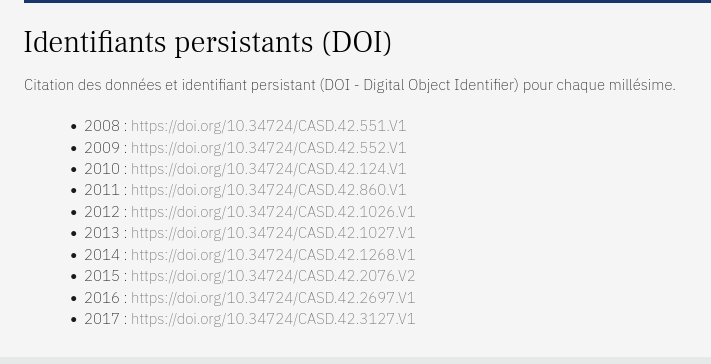
- Assigns DOI (= persistent reference)
- Versions
CASD data catalog (DDI)

Metadata
- access conditions
- content maintained in [DDI format]
Solution

Some services are serious about this

Github secret scanning
Footnotes
Bollen et al. 2015. “Social, Behavioral, and Economic Sciences Perspectives on Robust and Reliable Science.” National Science Foundation. https://www.nsf.gov/sbe/AC_Materials/SBE_Robust_and_Reliable_Research_Report.pdf.
Ambrus, Attila, Erica Field, and Robert Gonzalez. 2020. “Loss in the Time of Cholera: Long-Run Impact of a Disease Epidemic on the Urban Landscape.” American Economic Review, 110 (2): 475–525. https://doi.org/10.1257/aer.20190759
Ambrus, Attila, Field, Erica, and Gonzalez, Robert. Data and Code for: Loss in the Time of Cholera: Long-run Impact of a Disease Epidemic on the Urban Landscape. Nashville, TN: American Economic Association [publisher], 2020. Ann Arbor, MI: Inter-university Consortium for Political and Social Research [distributor], 2020-01-31. https://doi.org/10.3886/E111523V2
Weeden, K. A. (2023). Crisis? What Crisis? Sociology’s Slow Progress Toward Scientific Transparency . Harvard Data Science Review, 5(4). https://doi.org/10.1162/99608f92.151c41e3
United Nations Fundamental Principles of Official Statistics
National Academies of Sciences, Engineering, and Medicine. 2017. Principles and Practices for a Federal Statistical Agency: Sixth Edition. Washington, DC: The National Academies Press. https://doi.org/10.17226/24810.
Data Citation Synthesis Group: Joint Declaration of Data Citation Principles. Martone M. (ed.) San Diego CA: FORCE11; 2014 https://www.force11.org/group/joint-declaration-data-citation-principles-final
https://ers.usda.gov/data-products/area-and-road-ruggedness-scales/
https://datacolada.org/109, https://datacolada.org/110, https://datacolada.org/111, https://datacolada.org/112, https://datacolada.org/114, https://datacolada.org/118
Jones, M. (2024). Introducing Reproducible Research Standards at the World Bank. Harvard Data Science Review, 6(4). https://doi.org/10.1162/99608f92.21328ce3